
مدیریت رخداد در ITIL یعنی (Incident management) معمولا همراستا با Service Desk میباشد (service desk تنها نقطه تماس برای همه کاربرانی است که با IT در ارتباط هستند). آنچه در هنگام مختل شدن سرویس یا عدم ارائه عملکرد توافق شده از سرویس در ساعات نرمال سرویس دهی ضرورت دارد، بازگرداندن مجدد سرویس به عملکرد نرمال در سریعترین زمان ممکن است. همچنین هر شرایطی که احتمال اختلال یا خرابی سرویس در آن وجود دارد باید با ایجاد یک پاسخ به موقع، مانع از وقوع قطعی خرابی شود. این موارد، اهداف مدیریت رخداد هستند.
پرسنل Service desk معمولا به عنوان پشتیبانی سطح یک که شامل فعالیتهای زیر است، شناخته میشوند:
- شناسایی رخداد (Incident identification)
- ثبت رخداد (Incident logging)
- دسته بندی رخداد (Incident categorization)
- اولویت بندی رخداد (Incident prioritization)
- تشخیص اولیه (Initial diagnosis)
- ارجاع به پشتیبانی سطح دوم (در صورت لزوم)
- برطرف کردن رخداد (Incident resolution)
- بستن رخداد (Incident closure)
- برقراری ارتباط با عموم کاربران در طول حیات رخداد
وظیفه مدیریت رخداد در ITIL، تحلیل ریشه اصلی مشکل و شناسایی علت وقوع رخداد نمیباشد. بلکه تمرکز آن بر روی انجام فعالیت های لازم جهت بازگرداندن سرویس است. این کار نیازمند استفاده از یک راه حل یا اصلاح موقت است. یک ابزار مهم برای تشخیص رخدادها، پایگاه داده خطاهای شناخته شده (KEDB) است که توسط مدیریت مشکل (problem management) نگهداری میشود. KEDB هرگونه خطای شناخته شده یا مشکلی که منجر به وقوع رخدادها در گذشته شده است را شناسایی کرده و اطلاعاتی در خصوص راه حل های شناسایی شده ارائه میکند.
ابزار دیگری که توسط مدیریت رخداد مورد استفاده قرار میگیرد، مدل رخداد (incident model) نام دارد. رخدادهای جدید اغلب شبیه رخدادهایی هستند که در گذشته اتفاق افتاده است. یک مدل رخداد به تعریف موارد زیر میپردازد.
- مراحلی که باید برای کنترل و مدیریت رخداد در ITIL انجام شود، ترتیب مراحل و مسئولیتها.
- اقدامات پیشگیرانه ای که قبل از برطرف کردن رخداد باید انجام شود.
- بازه زمانی جهت برطرف ساختن رخداد
- روالهای ارجاع به مرجع بالاتر (Escalation procedures)
- نگهداری و محافظت از اسناد
مدل رخداد، فرآیند را ساده کرده و ریسک را کاهش میدهد. Incident management وابستگی و ارتباط نزدیکی با سایر فرآیندهای مدیریت سرویس دارد. این فرآیندها عبارتند از:
- مدیریت تغییر (Change Management). برطرف کردن یک رخداد ممکن است نیازمند ایجاد یک درخواست تغییر باشد. همچنین، از آنجا که درصد زیادی از رخدادها ناشی از اجرای تغییرات هستند، تعداد رخدادهای ناشی از تغییر به عنوان شاخص کلیدی عملکرد (KPI) برای مدیریت درنظر گرفته میشود.
- مدیریت مشکل (Problem management). همانطور که پیش تر به آن پرداخته شد، مدیریت رخداد در ITIL از یک KEDB که توسط مدیریت مشکل نگهداری میشود، استفاده میکند. Problem management نیز جهت انجام مسئولیتهای خود در راستای تشخیص خطاها و مشکلات به مجموعه کامل و دقیقی از داده های رخدادها نیاز است.
- مدیریت پیکربندی و دارایی سرویس (Service asset and configuration management). CMS یک ابزار مهم و ضروری برای رفع رخداد است زیرا ارتباطات بین اجزاء سرویس را شناسایی کرده و همچنین امکان یکپارچه سازی داده های پیکربندی را با داده های مشکلات و رخدادها فراهم میسازد.
- مدیریت سطح سرویس (Service level management). نقض سطح خدمات به خودی خود یک رخداد بوده و عاملی برای فرآیند مدیریت سطح سرویس است. همچنین توافق نامه های سطح سرویس (SLAs) ممکن است روشهای زمانبندی و ارجاع به مراحل بالاتر را برای انواع مختلفی از رخدادها تعریف کنند.
رخداد چیست؟
ITIL، رخداد را یک وقفه پیش بینی نشده یا کاهش کیفیت سرویس IT تعریف میکند. توافق نامه سطح سرویس نیز به تعریف سطح سرویس توافق شده بین سرویس دهنده و مشتری میپردازد.
رخدادها با درخواستها و مشکلات تفاوت دارند. رخداد، باعث قطع شدن سرویسهای نرمال میشود. مشکل به وضعیتی گفته میشود که بواسطه یکسری رخدادهای متعدد با علائم مشابه شناسایی میشود. Problem management ریشه مشکل را شناسایی و رفع میکند. Incident management سرویسهای IT را به حالت نرمال برمیگرداند. درخواستهای اجرا جزو درخواستهای رسمی بوده که ارائه کننده مواردی از قبیل آموزش، اطلاعات حساب، سخت افزار جدید، تخصیص مجوز و هر آنچه که IT service desk ارائه میکند، میبلشند. یک درخواست ممکن است قبل از اجرا به تاییدیه نیاز داشته باشد.
رخدادها عملکرد نرمال سرویس را مختل میکنند، مانند زمانی که کامپیوتر یک کاربر خراب میشود، یا زمانی که اتصال VPN برقرار نمیشود و یا زمانی که پرینتر از کار می افتد. اینها وقایع غیر منتظره ای هستند که نیازمند رسیدگی از جانب سرویس دهنده بوده تا مجددا به حالت نرمال خود بازگردانده شوند.
مدیریت رخداد در ITIL چیست؟
هنگامی که اکثر مردم درباره فناوری اطلاعات فکر می کنند، مدیریت رخداد در ITIL فرایندی است که معمولا به ذهن آنها میرسد. این فرآیند تنها بر مدیریت و ارجاع رخداد به سطوح بالاتر و بازگرداندن سرویس به سطوح تعریف شده تمرکز دارد. Incident management با تحلیل علل بوجود آورنده رخداد و یا حل مشکلات سر و کار ندارد. هدف اصلی آن دریافت رخدادهای گزارش شده کاربران و رفع آنها و در نهایت بستن این رخدادها است. مدیریت رخداد در ITIL مؤثر، ارزش مداوم برای کسب و کار ایجاد میکند. بعلاوه این امکان را فراهم میاورد تا رخدادها در بازه زمانی پیش بینی نشده برطرف شوند. برای اکثر سازمان ها، این فرایند از رفت و برگشت ایمیلها به یک سیستم تیکتینگ رسمی با اولویت بندی، طبقه بندی و الزامات SLA پشتیبانی میکند. ایجاد ساختارهای رسمی زمانبر است اما خروجی بهتری برای کاربران، تیم پشتیبانی و کسب و کار دارد. داده های جمع آوری شده از پیگیری رخدادها به مدیریت بهتر مشکلات و تصمیم گیری های کسب و کار کمک میکند. ایجاد مدلهای رخداد نیز در مدیریت رخداد انجام شده و به کارکنان پشتیبانی کمک میکند تا بصورت کارامد مشکلات و مسائل تکراری را برطرف نمایند. این مدلها به کارکنان پشتبانی امکان میدهند تا رخدادها را از طریق فرآیندهای تعریف شده برای کنترل رخدادها به سرعت رفع کنند. در برخی سازمانها، یک تیم اختصاصی برای مدیریت رخداد در نظر گرفته شده است. در اکثر کسب و کارها، این وظیفه به service desk و صاحبان آن، مدیران و سهامداران واگذار می شود. در دسترس بودن مدیریت رخداد، پیاده سازی و پشتیبانی از آن را آسان کرده است، زیرا ارزش آن برای کاربران در تمام سطوح سازمان آشکار است. هر فردی با مسائل و مشکلاتی روبه رو میشود که برای حل و رسیدگی سریع به آنها ، به دانش و مهارت تیم پشتیبانی نیاز دارد.
- مدیریت مؤثر رخدادها به چندین بخش کلیدی نیاز دارد:
- توافق نامه سطح سرویس بین سرویس دهنده و مشتری که اولویتها، مسیرهای ارجاع و مدت زمان پاسخ و رفع رخداد را تعریف میکند.
- مدلهای رخداد یا الگوها که قادر است رخدادها را بطور مؤثر رفع کند.
- دسته بندی انوااع رخدادها برای جمع آوری بهتر داده ها و مدیریت مشکلات
- توافق بر اولویتها، دسته بندی ها و وضعیتهای رخدادها
- ایجاد یک فرآیند اصلی پاسخگویی به رخداد
- توافق بر تخصیص نقش مدیریت رخداد
مورد شماره پنج در مدیریت رخداد در ITIL اهمیت ویژه ای دارد. مدیر رخداد مسئول رسیدگی به رخدادهایی است که نمی توانند در قالب SLA های توافق شده برطرف شوند، مانند مواردی که service desk قادر به برطرف کردن آنها نمیباشد. مدیر رخداد در بسیاری از سازمانها ممکن است مدیر عملیات IT یا سرپرست فنی IT باشد.
عملکرد اصلی مدیریت رخداد: The service desk
مدیریت رخداد در ITIL چندین زیرمجموعه دارد. مهم ترین زیرمجموعه مدیریت رخداد در ITIL، service desk است. Service desk با نام help desk نیز شناخته میشود. Service desk تنها نقطه تماس برای کاربران جهت گزارش رخدادها است. بدون وجود service desk کاربران بدون هیچ گونه محدودیتی در ساختار یا اولویتها، با تیم پشتبانی تماس میگیرند. این بدین معناست که ممکن است هنگامیکه تیم پشتیبانی در حال رسیدگی به رخدادی با اولویت پایین است، رخدادهای با اولویت بالا نادیده گرفته شوند. رخدادهایی که اولویت پایینی دارند مانند تعمیر ایستگاه dicking نامناسب که ممکن است چند هفته حل نشده باقی بماند زیرا کارکنان پشتیبانی IT در حال رسیدگی به مسائل مهمی هستند که در آن زمان به آنها داده شده است. ساختار service desk امکانی فراهم می آورد تا تیم پشتیبانی با سرعت به مشکلات همه رسیدگی کند، مدلهای سلف- سرویس ایجاد کند، روند داده های It را جمع آوری کند، انتقال دانش بین کارکنان پشتیبانی را افزایش دهد و از problem management پشتیبانی کند.
Service desk به دو لایه پشتیبانی تقسیم میشود. لایه اول برای مسائل و مشکلات اساسی است، مانند بازنشانی رمز عبور و عیب یابی های اصلی کامپیوتر. رخدادهای لایه اول غالبا به مدلهای رخداد تبدیل میشوند، زیرا الگوهای ایجاد آنها ساده بوده و این رخدادها اغلب رخ میدهند. به عنوان مثال، یک مدل الگو برای بازنشانی رمز عبور، شامل دسته بندی رخداد (دسته “حساب” و نوع “Reset Password”، برای مثال)، الگویی از اطلاعاتی است که کارکنان پشتیبانی انها را تکمیل کرده (مانند نام کاربری و تاییدیه) و به مقالات پایگاه دانش داخلی و خارجی جهت پشتیبانی از رخداد، پیوست میکنند. رخدادهای لایه اولی که اولویت پایینی دارند در هیچ شرایطی بر روی کسب و کار اثر نداشته و میتوانند توسط کاربران برطرف شوند.
لایه دوم مربوط به مسائل و مشکلاتی است که به مهارت، آموزش یا دسترسی بیشتری نیاز دارند. برای مثال ممکن است بازنشانی RSA token نیازمند ارجاع به لایه دوم است. برخی سازمانها رخدادهایی که توسط VIP ها گزارش شده اند را به عنوان رخداد لایه دومی درنظر میگیرند تا کیفیت بالاتری از خدمات را برای این کارکنان فراهم کنند. رخدادهای لایه دوم ممکن است مسائل و مشکلاتی با اولویت متوسط باشند که نیازمند پاسخ سریع از service desk هستند.
تخصیص درست لایه ها و اولویت بندی ها زمانی صورت میگیرد که اکثر رخدادها به لایه اول / اولویت پایین، برخی رخدادها به لایه دوم و تعداد کمی از رخدادها به لایه سوم انتقال یابند. رخدادهایی که نیاز به تشدید فوری دارند، به عنوان رخدادهای اصلی در نظر گرفته شده و میبایست با مشارکت کل تیم پاسخ داده شوند. رخدادهای اصلی در ITIL به رخدادهایی گفته میشود که نشان دهنده اختلالات عمده در کسب و کار هستند. این رخدادها همیشه اولویت بالایی دارند و به سرعت توسط service desk و کارکنان سطوح بالاتر پاسخ داده میشوند. این رخدادها در ساختار پشتیبانی لایه ای، سومین لایه محسوب میشوند و برای problem management گزینه های مناسبی هستند.
فرآیند رخداد
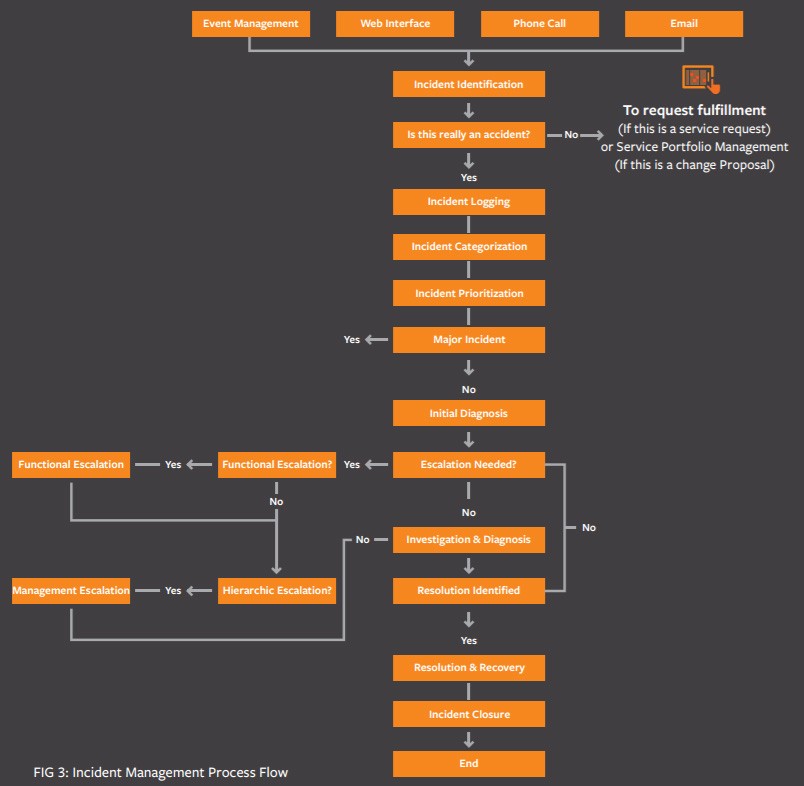
در ITIL، رخدادها از یک جریان کاری ساختاریافته عبور کرده و بهترین نتایج و کارایی را برای سرویس دهندگان و مشتریان به ارمغان می آورند. بر اساس توصیه های ITIL ، فرآیند مدیریت رخداد مراحل زیر را در بر میگیرد:
شناسایی رخداد
ثبت رخداد
دسته بندی رخداد
اولویت بندی رخداد
پاسخ رخداد
- تشخیص اولیه
- ارجاع رخداد به سطوح بالاتر
- تحقیق و تشخیص
- اجرا و بازیابی
- بستن رخداد
فرآیند رخداد امکان کنترل بهتر رخداد را فراهم کرده و بهبود مستمر سرویس را تضمین میکند.
اولین مرحله در زمان حیات رخداد، شناسایی رخداد است. رخدادها از جانب کاربران و به شیوه مجاز سازمان، ایجاد میشوند.
. منابع گزارش های رخداد عبارتند از پاکسازی، خدمات self-service، تماس های تلفنی، ایمیلها، گفتگوهای پشتیبانی و اخطارهای خودکار مانند نرم افزار مانیتورینگ شبکه یا ابزارهای پویش سیستم. در گام بعدی، service desk در خصوص اینکه مساله بوجود آمده آیا واقعا یک رخداد است یا یک درخواست، تصمیم گیری میکند. طبقه بندی و کنترل درخواستها با رخدادها متفاوت بوده و رخدادها زیرمجموعه ای از درخواستها هستند.
پس از شناسایی رخداد، service desk رخداد را به عنوان یک درخواست ثبت میکند. این درخواست باید شامل اطلاعاتی همچون نام کاربری و اطلاعات تماس، شرح رخداد و زمان و تاریخ گزارش رخداد (برای انطباق با SLA) باشد. همچنین فرآیند ثبت (logging process) شامل دسته بندی،اولویت بندی و مراحلی است که service desk آنها را تکمیل میکند.
دسته بندی رخدادها یک مرحله مهم و ضروری در فرآیند مدیریت رخداد در ITIL است. دسته بندی شامل تخصیص یک دسته و حداقل یک زیر شاخه به رخداد است. این عمل چندین هدف را دنبال میکند. نخست به service desk امکان میدهد تا رخدادها را بر اساس دسته بندی و زیرشاخه های آنها، مرتب و مدل سازی کند. همچنین امکان اولویت بندی خودکار برخی رخدادها را فراهم می آورد. برای مثال، یک رخداد ممکن است در دسته بندی “شبکه” با زیر شاخه “قطعی شبکه” قرار گیرد. این دسته بندی در برخی سازمانها به عنوان یک رخداد با اولویت بالا در نظر گرفته میشود که نیاز به یک پاسخ سریع دارد. هدف سوم فراهم سازی امکان پیگیری دقیق رخدادها میباشد. هنگامیکه رخدادها دسته بندی میشوند، الگوها شکل میگیرند. به آسانی میتوان اندازه گیری کرد که رخدادهای خاص هر چند وقت یکبار رخ میدهند و بر اساس روند وقوع رخدادها، بخش هایی را که به آموزش یاproblem management دارند، مشخص نمود. برای مثال، هنگامیکه مدیر ارشد مالی اطلاعات کافی برای تصمیم گیری در خصوص محصول جدید سخت افزاری داشته باشد، به سادگی برای خرید محصول متقاعد خواهد شد.
اولویت بندی رخدادها برای تبعیت از مواردی که در توافق نامه سطح سرویس لحاظ شده، بسیار اهمیت دارد. اولویت یک رخداد بر اساس میزان تاثیر آن بر کاربران و کسب و کار و همچنین فوریت آن، تعیین میشود. فوریت بدین معناست که درخواست با چه سرعتی انجام شود. سطح تاثیر به معنای اندازه گیری میزان آسیبهای احتمالی است که یک رخداد ممکن است وارد کند.
رخدادهای با اولویت پایین به رخدادهایی گفته میشود که در عملکرد کاربران و شرکت خللی وارد نکرده و قابل سازماندهی هستند.
رخدادهای با اولویت متوسط بر تعداد کمی از کارکنان تاثیر گذاشته و تا حدودی کار آنها را مختل میکنند. مشتریان نیز ممکن است کمی تحت تاثیر قرار گرفته و یا دچار مشکل شوند.
رخدادهای با اولویت بالا بر گستره وسیعی از کاربران یا مشتریان اثر گذاشته، کسب و کار را مختل کرده و ارائه سرویس را تحت تاثیر قرار میدهد. این رخدادها تقریبا همیشه بخشهای مالی را نیز تحت تاثیر قرار میدهند.
پس از آنکه رخداد شناسایی، دسته بندی، اولویت بندی و ثبت گردید، service desk میتواند رخداد را کنترل و برطرف کند. یک رخداد در پنج مرحله برطرف میشود:
شناسایی اولیه (Initial Diagnosis): این اتفاق زمانی رخ میدهد که کاربر مشکل خود را شرح داده و سوالات عیب یابی (Troubleshooting) را پاسخ میدهد.
ارجاع رخداد به سطوح بالاتر (Incident Escalation): این اتفاق زمانی رخ میدهد که یک رخداد به پشتیبانی حرفه ای نیاز داشته باشد، مانند اعزام کارشناس در محل یا درخواست کمک از کارکنان آموش دیده در بخش پشتیبانی. همانطور که پیش تر مطرح گردید، اکثر رخدادها باید توسط کارکنان پشتیبانی در لایه نخست برطرف شده و به لایه های بالاتر ارجاع داده نشوند.
بررسی و تشخیص (Investigation and Diagnosis): این فرآیندها در طول عیب یابی و در زمانی که فرضیه اولیه رخداد صحیح باشد، رخ میدهند. بعد از آنکه رخداد تشخیص داده شد، کارکنان میتوانند راه حل ارائه کنند، مانند تغییر تنظیمات نرم افزار، ارائه patch نرم افزار، یا سفارش سخت افزار جدید.
برطرف ساختن رخداد و بازیابی (Resolution and Recovery): این کار زمانی انجام میشود که service desk تایید کند سرویس کاربر به سطح SLA مورد انتظار، بازیابی شده است.
بستن رخداد (Incident Closure): در این مرحله رخداد بسته شده و فرآیند رخداد به پایان میرسد.
نمودار جریان فرآیند مدیریت رخداد (Incident management process flow diagram)
وضعیتهای رخداد (Incident statuses)
وضعیتهای رخداد نشان دهنده فرآیند رخداد هستند. این وضعیتها عبارتند از:
- جدید (New)
- تخصیص یافته (Assigned)
- در جریان (In progress)
- در انتظار (On hold or pending)
- حل شده (Resolved)
- بسته (Closed)
وضعیت “جدید” نشان هنده آن است که service desk رخداد را دریافت کرده اما هنوز آن را به عوامل پشتیبانی تخصیص نداده است.
وضعیت “تخصیص یافته” نشان دهنده آن است که رخداد به یکی از کارکنان service desk تخصیص یافته است.
وضعیت “در جریان” نشان دهنده آن است که رخداد به یکی از عوامل پشتیبانی تخصیص داده شده اما برطرف نشده است.
وضعیت “در انتظار” نشان دهنده آن است که رخداد نیازمند اطلاعات یا پاسخی از سوی کاربر یا شخص ثالث دیگری است. هنگامیکه رخداد به وضعیت “در انتظار” میرود، مدت زمان مجاز پاسخ که در SLA تعریف شده تا زمانیکه پاسخی از سمت کاربر یا فروشنده دریافت نشود، ثابت باقی میماند.
وضعیت “حل شده” بدین معناست که service desk تایید کند رخداد برطرف شده و سرویس کاربر به سطح توافق شده در SLA بازگشته است.
وضعیت “بسته” نشان دهنده آن است که رخداد برطرف شده است و هیچ اقدام دیگری نمیتواند انجام شود.
مدیریت رخداد در ITIL ، رخدادها را از طریق service desk دنبال کرده تا در جریان روند رخدادها در دسته بندی های انجام شده و همچنین زمان هر وضعیت قرار گیرد. آخرین بخش از مدیریت رخداد در ITIL ، ارزیابی اطلاعات جمع آوری شده است. داده های رخدادها به سازمانها کمک میکند تا در خصوص بهبود کیفیت سرویسهای ارائه شده تصمیم گیری کنند و حجم رخدادهای گزارش شده را کاهش دهند. مدیریت رخداد در ITIL تنها یکی از فرآیندهای چارچوب service operation است.
ارزش مدیریت رخداد برای کسب و کار
نحوه مدیریت رخدادهای شرکتی می تواند باعث افزایش اعتیار و پایگاه مشتری یک کسب و کار شود و یا آسیب رسیدن به آن شود. برگزاری روخدادها، چه به صورت گردهمایی های کوچک با حامیان مالی یا کارمندان باشد و چه روخدادهای استارتاپی هزار نفری، به شرکت اجازه می دهد تا برند خود را تبلیغ و روابط جدیدی را ایجاد کند.
رخدادها می توانند به افزایش شهرت یک برند کمک کنند. با داشتن شهرت خوب، مشتریان به احتمال بیشتری برای دریافت خدمات با یک شرکت ارتباط برقرار می کنند. این مشتریان همچنین با احتمال بیشتری محصولات جدید را در زمان عرضه امتحان می کنند و از برندی که با ارزش ها و ترجیحات خود همسو می بینند حمایت می کنند.
هماهنگی موثر رخداد می تواند همان تفاوتی باشد که بین شرکتی با رخدادهای متوسط با تعداد محدودی شرکت کننده و کسب و کاری با توانایی حفظ تعاملات درگیرکننده و بازگشت سرمایه مناسب وجود دارد.
مدیریت رخداد همچنین این توانایی را ایجاد می کند تا شرکت یک گام به موفقیت نزدیک تر شود. بسته به صنعت، نتیجه مدیریت موثر رخدادها می تواند شامل دید شدن بیشتر، روابط جدید بین فروشندگان و پایگاه مشتری گسترده تر باشد.
اگر یک کسب و کار مشتریان بازگشتی و شرکت کنندگانی خوشحال داشته باشد، می تواند به خوبی ارزش و مزایای مدیریت رخداد را به نمایش بگذارد و در عین حال از محدوده بودجه تعیین شده نیز فراتر نرود. علاوه بر این، گزارش های پس از آن برای بهبود روخدادها برای دفعات بعدی انجام می شود تا از شنیده شدن و در نظر گرفته شدن نظرات مهمانان و شرکت کنندگان اطمینان حاصل شود.
مزیت های مدیریت رخداد برای سازمان ها
- افزایش بهره وری: بهبود در دسترس بودن خدمات فناوری اطلاعات به این معنی هستش که کارمندان می توانند بر روی وظایف اصلی خود تمرکز کنند بدون اینکه مشکلات فنی مانع شوند.
- افزایش رضایت مشتری: حل سریع تر حوادث، منجر به رضایت بیشتر مشتریان و بهبود شهرت برند میشود.
- شناسایی پیشگیرانه نقاط ضعف خدمات: تجزیه و تحلیل رخدادها به شناسایی مشکلات تکراری و بهبودهای خدمات کمک میکند و از وقوع رخدادها در آینده جلوگیری میکند.
- تصمیمگیری بهبودیافته: دادههای جمعآوریشده از طریق مدیریت رخداد، بینشهای ارزشمندی را برای اطلاعرسانی تصمیمهای استراتژیک در مورد زیرساختهای فناوری اطلاعات و تخصیص منابع فراهم میکند.
- بهبود کارایی و مقرون به صرفه بودن: فرآیندهای استاندارد و نقشها و مسئولیتهای روشن، رسیدگی به حوادث را ساده میکند و زمان و تلاش تلف شده را کاهش میدهد.
- کار تیمی و همکاری بهتر: مدیریت رویداد هماهنگی بین تیمهای فناوری اطلاعات و سایر بخشها را تقویت میکند که منجر به عیبیابی و حلوفصل مؤثرتر میشود.
- توسعه پایگاه دانش: مستندسازی روشهای حل حادثه، پایگاه دانش ارزشمندی را برای مراجعات بعدی ایجاد میکند که به نفع کارمندان آینده است و کار تکراری را کاهش میدهد.
- اندازهگیری دقیق عملکرد: SLAها و معیارهای واضح، نظارت مناسب بر عملکرد مدیریت حادثه را امکانپذیر میسازد و امکان بهینهسازی مبتنی بر داده را فراهم میکند.
- بهبود مستمر: تجزیه و تحلیل روندها و یادگیری از حوادث گذشته منجر به بهبود مستمر در فرآیند مدیریت حادثه میشود.
سوالات متداول
- مدیریت رخداد چیست؟
مدیریت رخداد در ITIL یعنی (Incident management) معمولا همراستا با Service Desk میباشد (service desk تنها نقطه تماس برای همه کاربرانی است که با IT در ارتباط هستند). آنچه در هنگام مختل شدن سرویس یا عدم ارائه عملکرد توافق شده از سرویس در ساعات نرمال سرویس دهی ضرورت دارد، بازگرداندن مجدد سرویس به عملکرد نرمال در سریعترین زمان ممکن است. - رخداد چیست؟
ITIL، رخداد را یک وقفه پیش بینی نشده یا کاهش کیفیت سرویس IT تعریف میکند. توافق نامه سطح سرویس نیز به تعریف سطح سرویس توافق شده بین سرویس دهنده و مشتری میپردازد. - وضعیتهای رخداد چیست؟
جدید (New) – تخصیص یافته (Assigned) – در جریان (In progress) – در انتظار (On hold or pending) – حل شده (Resolved) – بسته (Closed)